오늘 새벽까지 ELK Stack을 맥북에 설치하고 열심히 갖고 놀아보았다.
모니터링 시스템은 올해 초 시스템 분석설계 수업을 들으면서 가장 만들어보고 싶었던 내용 중 하나였다.
더 정확하게는 자료흐름도를 공부하며 자료흐름을 추적할 수 있는 시스템이 존재하면 좋겠다고 생각해 왔다.
예를 들어 내가 포트폴리오로 만든 동영상 플랫폼 중 파일 업로드는 아래와 같은 구조를 갖고 있다.
1. 사용자가 웹에서 파일을 업로드한다.
2. 백엔드 서버가 사용자의 업로드 요청을 처리한다.
1) 동영상의 ID를 만들어 사용자에게 반환한다. (DB에 해당 ID로 내용을 저장한다.)
2) 동영상을 서버로 수신한다.
3) 임시 위치에 동영상을 저장한다.
4) DB에 파일 업로드 처리를 저장한다.
5) 사용자에게 저장 성공 메시지를 보낸다.
6) 후처리 1 이벤트를 발행한다.
3. 후처리1 서버에서 동영상 후처리 작업을 진행한다.
1) 후처리 이벤트를 소비한다.
2) DB에 해당 동영상의 처리 과정을 갱신한다.
3) 후처리 1을 수행한다.
4) 후처리1 완료를 DB에 갱신한다.
5) 사용자에게 후처리1 알림을 보낸다.
6) 후처리 2 이벤트를 발행한다.
4. 후처리2 서버에서 동영상 후처리 작업을 진행한다.
1) 후처리2 메시지를 소비한다.
2) DB에 해당 동영상의 처리 과정을 갱신한다.
3) 후처리 2를 수행한다.
4) 후처리2 완료를 DB에 갱신한다.
5) 사용자에게 후처리2 알림을 보낸다.
6) 파일 스토리지 저장 이벤트를 발행한다.
5. 파일 스토리지 저장 서버에서 파일을 온라인 스토리지로 저장한다.
1) 저장 메시지를 소비한다.
2) DB에 해당 동영상의 처리 과정을 갱신한다.
3) 저장을 수행한다.
4) 저장 완료를 DB에 갱신한다.
5) 사용자에게 저장 완료 알림을 보낸다.
준실시간으로 서버의 자원과 상태를 측정하는 지표가 metric이다. 이는 아래의 구조로 모니터링하고 있다.
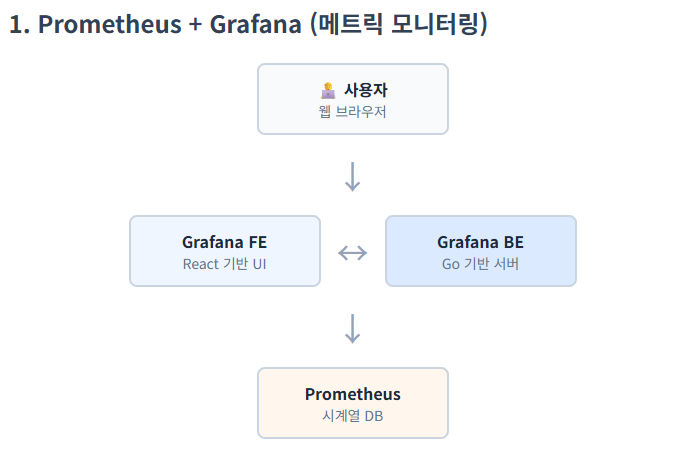
그리고 각 서버가 해당 처리과정을 기록하는 방법은 로그이다.
로그를 남길 때, 동영상의 ID와 처리 상태, 처리하는 시스템, 스레드 등의 정보를 입력하고 이를 ES로 전송한다.
1-5번이 수행되는 동안 서버는 다양한 로그를 생성한다.
그리고 해당 로그들은 시간 순서대로 나열하면 특정 ID를 지닌 자료가 어떤 식으로 흐름을 타고 처리되는지 알 수 있다.

위와 같이 하나의 요청(동영상 ID)이 여러 시스템을 거치는 전체 흐름을 추적하고, 각 단계의 로그와 해당 시점의 시스템 메트릭(서버자원)을 함께 분석하는 것이 현대 모니터링 시스템의 핵심적인 목표라고 한다.
이미 많은 모니터링 도구들이 APM(Application Performance Monitoring)과 분산 추적(Distributed Tracing)이라는 기술을 통해 이 기능을 구현하고 있다.
분산 추적
처음 사용자 요청이 시작될 때, 고유한 ID(Trace ID)를 부여하고, 이 요청이 여러 서버와 서비스를 거칠 때마다 전달된다.
만약 위의 업로드 로직에 적용된다면 다음과 같다.
1. 사용자가 동영상 업로드를 시작하면, 백엔드 서버는 동영상 ID와 별개로 요청 전체를 대표하는 TraceID를 생성한다.
2. 백엔드 서버는 로그를 남길 때, 동영상 ID와 함께 이 TraceID를 포함한다.
3. 백엔드 서버가 이벤트를 발행할 때, 이벤트 메시지 안에 이 TraceID를 함께 담아 보낸다.
4. 이벤트 소비 서버는 로그를 남길 때 메시지에서 꺼낸 TraceID를 그대로 사용한다.
5. 이 과정이 끝까지 계속 반복된다.
이렇게 모든 시스템이 동일한 TraceID를 공유하며 로그를 남기면, 모니터링 시스템에선 이 TraceID 하나로 전체 처리 과정을 실에 꿰인 구슬처럼 한 번에 엮어서 볼 수 있게 된다.
APM: 메트릭, 로그, 트레이스의 통합
APM 도구는 바로 이 분산 추적(Trace) 데이터를 기반으로, 각 처리 단계의 메트릭(Metric)과 로그(Log)를 하나로 묶어 보여주는 설루션이다.
Elastic APM, Jaeger, Zipkin, Grafana Tempo, Datadog, New Relic과 같은 도구들이 있다고 한다.
이 도구들을 사용하면 전체 흐름을 시각화할 수 있다.

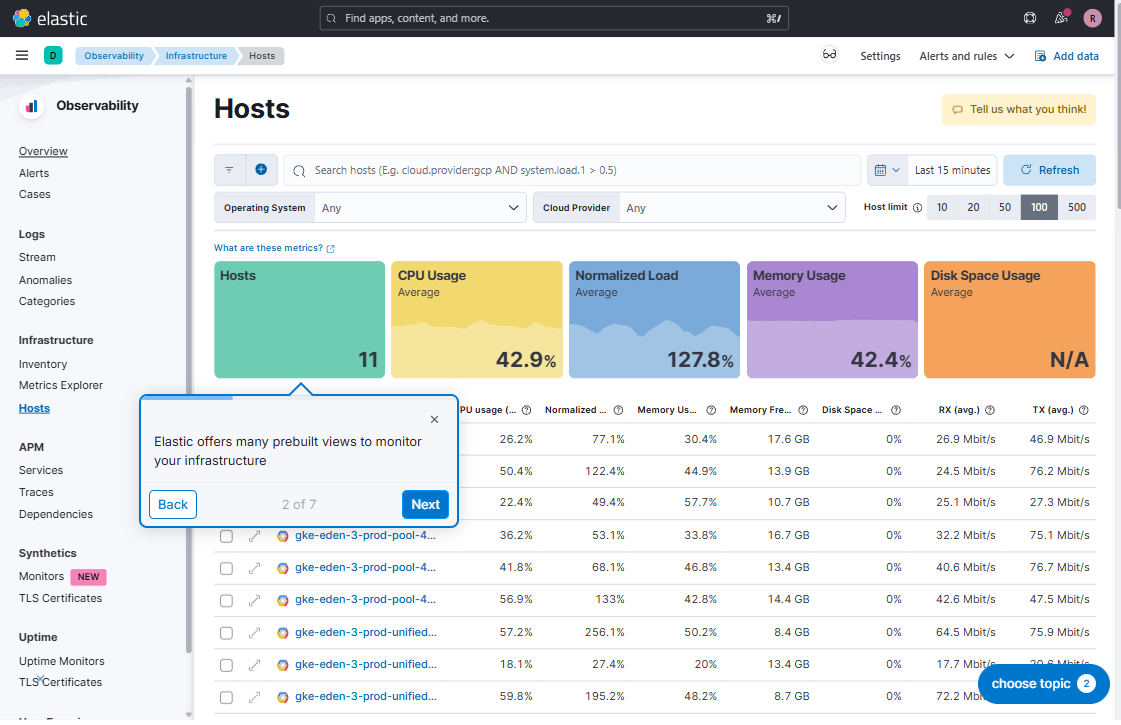
TraceID를 기준으로, 동영상 업로드 요청이 벡엔드 서버에서 몇 초, 후처리 1 서버에서 몇 분, 후처리 2 서버에서 몇 분 걸렸는지 한눈에 차트로 확인할 수 있다. 즉, 어떤 단계에서 병목이 있는지, 성능 개선이 필요한지 한눈에 확인할 수 있다.
나는 항상 로그에 남은 시간을 직접 계산해서 병목 지점을 찾았었는데... 이래서 새로운 기술에 대해 항상 연구해야 한다...
로그-메트릭 연동을 통해 클릭 한 번으로 그 단계가 실행될 때 남겨진 모든 로그와 해당 시점의 서버 CPU/메모리 사용량 그래프로 바로 이동하여 확인할 수 있다. 이것 역시... 만약 내가 작년에 이런 툴을 사용하고 있었다면, 파일의 전송 과정에서 네트워크 드라이브와 관련된 장애 문제를 바로 확인할 수 있었을 것이다... 괜히 애꿎은 내 비즈니스 로직만 한 줄씩 로그를 남겨가며 조회했었는데...
워낙 상용 시스템이든, 오픈소스 시스템이든 잘되어있는 상태라 조금 김이 빠지긴 한다.
이런 시스템을 내가 회사에 있을 때, 서버 하나를 이용해서 구축해 놓았으면 얼마나 좋았을까?
회사에 다니고 있었으면, 아직도 일에 치여 이런 부분까지 시야를 갖진 못했을 것 같긴 하지만......
'공부' 카테고리의 다른 글
| [BE] 알림 기능 리팩토링 - 단일 책임 원칙 (1) | 2025.06.10 |
|---|---|
| [React] 참조 동일성 (1) | 2025.06.08 |
| [모니터링] Prometheus + SpringBoot (1) | 2025.06.06 |
| [모니터링] Prometheus + Grafana (0) | 2025.06.06 |
| [BE] RabbitMQ 장애 - 메시지 중복 처리, 메모리 부족, 디스크 공간 부족 (0) | 2025.06.05 |

