최근 개인 개발용으로 Firestore라는 GCP의 기능을 사용하게 되었다.
Firestore는 구글의 모바일 및 웹 애플리케이션 개발 플랫폼인 Firebase에서 제공하는 NoSQL 클라우드 데이터베이스이다.
앱의 데이터를 저장하고, 실시간으로 여러 사용자와 동기화하며, 필요할 때마다 쉽게 꺼내 쓸 수 있게 해주는 매우 유연하고 강력한 '디지털 파일 캐비닛'이라고 생각할 수 있다.
Firestore의 특징은 아래와 같다.
실시간 동기화 지원
- 데이터베이스의 데이터가 변경되면, 해당 데이터를 보고 있는 모든 앱에 거의 즉시 변경 사항이 전달된다.
- 채팅 앱에서 메시지 교환, 여러 사용자가 함께 편집하는 문서 도구, 실시간 주식 시세 앱 등을 만들 때 유용하다.
오프라인 지원
- 모바일 앱 사용자가 지하철이나 비행기 안처럼 인터넷이 불안정하거나 끊긴 환경에 있더라도 앱이 원활하게 동작한다.
- Firestore SDK가 데이터를 기기 내에 캐시 해두고, 사용자가 데이터를 읽거나 쓰는 작업을 처리한다. 이후 인터넷이 다시 연결되면 변경 사항을 서버와 자동으로 동기화한다.
서버리스
- 개발자가 데이터베이스 서버를 직접 구축, 설정, 관리, 확장할 필요가 없다. 구글이 알아서 위의 내용을 처리해 준다.
- 개발자는 오직 앱 로직과 데이터 구조에만 집중할 수 있어서 개발 속도가 매우 빨라진다.
유연한 NoSQL 데이터 모델
- Firestore는 데이터를 Collection과 Document라는 구조로 저장한다.
- Document : 데이터를 담는 개별 파일, 내부에 key-value 쌍으로 다양한 데이터 저장
- Collection : Document들을 담는 폴더
- 이 구조는 정해진 틀(Schema)이 없어 매우 유연하며, 복잡하고 계층적인 데이터를 저장하기에 용이하다.
https://firebase.google.com/docs/firestore?hl=ko
Firestore | Firebase
Google Cloud 인프라를 기반으로 하는 유연하고 확장 가능한 NoSQL 클라우드 데이터베이스를 사용해 클라이언트 측 개발 및 서버 측 개발에 사용되는 데이터를 저장하고 동기화하세요.
firebase.google.com
위의 특징들은 쓰기 위해서 찾은 공식 문서의 내용을 요약한 거지만, 사실 내게 필요한 것은 무료로 사용할 수 있는 DB였다.
개인 개발용 앱에서 하루에 약 5000건의 데이터를 쓰고 읽는 기능이 필요했다.
DB를 쓰면 좋겠지만, 내 GCP의 Comput Engine(CE)는 너무 갸녀린 아이라서 차마 DB까지 설치할 수가 없었다.
Redis도 마찬가지의 이유에서 탈락...
좋은 방법이 없을까 알아보던 도중, GCP의 Firestore가 무료 읽기 쓰기를 일 20,000건까지 제공한다는 사실을 확인했다.
약간 느린 건 큰 문제가 되지 않았고, NoSQL을 공부도 할 겸 이 데이터베이스를 채택하게 되었다.
** 실제로 사용하게 된다면 Redis를 사용해서 구현할 기능이지만, 나는 가난한 개발자다.
구글 클라우드 플랫폼(GCP)에서 Firestore를 검색한다.
나는 GCP를 기존에 이용하던 사용자고, 프로젝트가 생성되어 있기 때문에 사용 버튼만 눌러도 자동으로 프로젝트와 연결되었다.
원래는 아래의 데이터베이스 테이블은 빈칸 이어야 한다.
파란색 버튼(FIRESTORE 데이터베이스 만들기)을 눌러 데이터베이스를 생성한다.
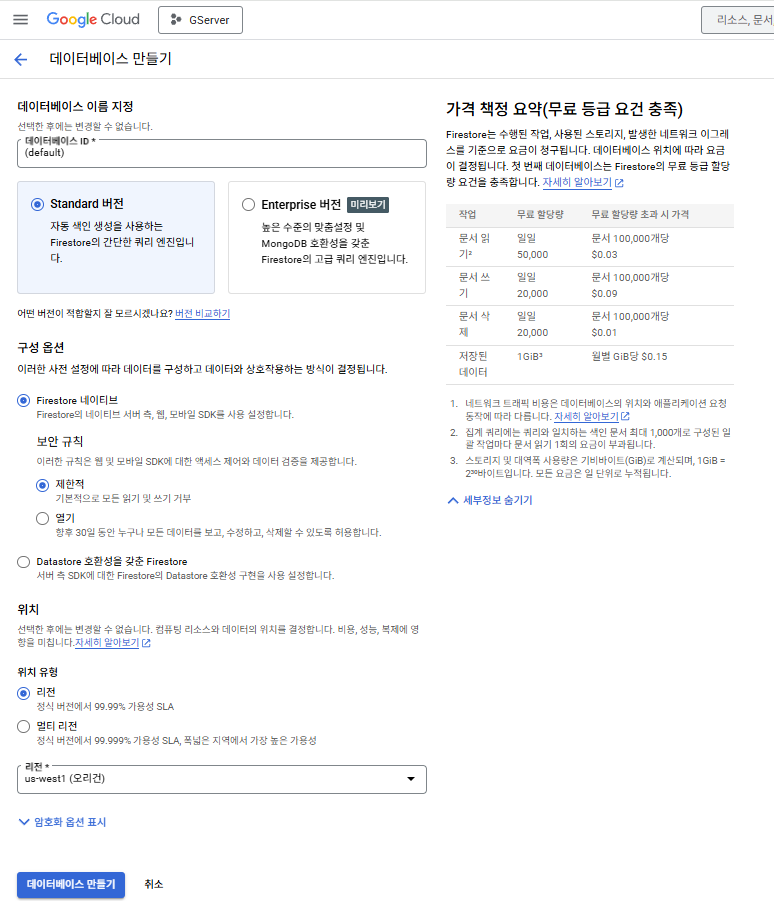
각종 설정을 적용한다. 나는 리전 외의 설정은 변경하지 않았다.
리전은 실제 생성한 데이터베이스가 위치하는 물리적 위치를 의미한다.
나는 GCP의 모든 운영 서버를 us-west1 (오리건)에 두고 사용하기 때문에 해당 위치로 설정했다.
오른쪽에 위치한 서비스 과금에 대한 내용도 살펴보고 넘어가야 한다.
쓰기 작업은 일 2만 건, 읽기 작업은 일 5만 건의 무료 사용량을 제공한다.
나는 개인 용도로 사용하고, 일 사용량이 5천-1만 이하이므로 큰 문제가 없지만, 반드시 트래픽과 비용을 고려해서 적용해야 한다.
데이터베이스 만들기에 성공하면 다음과 같은 화면이 나온다.

일단 이 상태가 나오면 성공이다.
이제 Java에서 이 데이터베이스에 접근해서 쓰고, 읽기 작업을 수행한다.
implementation 'com.google.cloud:google-cloud-firestore:3.31.6'
나는 Gradle로 프로젝트를 관리하므로 위의 의존성을 추가했다.
import com.google.cloud.firestore.Firestore;
import com.google.cloud.firestore.FirestoreOptions;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FirestoreConfig {
@Bean
public Firestore firestore() {
// 이 코드는 GCP 환경(Cloud Run 등)에서 실행될 때,
// 자동으로 해당 환경의 프로젝트 ID와 인증 정보를 사용하여 Firestore 객체를 생성합니다.
// 로컬에서 테스트할 때는 'gcloud auth application-default login' 명령어로 인증해야 합니다.
return FirestoreOptions.getDefaultInstance().getService();
}
}
Firestore를 사용하기 위해 DB 접근 객체를 Bean으로 생성해 준다.
위의 주석에서 설명하듯, GCP 환경에서 실행되는 경우에는 자동으로 프로젝트 ID와 인증 정보를 가져와서 객체를 생성한다.
하지만 로컬에서 테스트를 하기 위해서는 Local에 인증 정보가 있어야 한다.
- 나는 gcloud cli를 다운로드하고, 위의 명령어를 사용해서 인증한 후 개발했다.
@Service
@AllArgsConstructor
public class RateLimitServiceImpl implements RateLimitService {
private static final int DAILY_LIMIT = 3;
private final Firestore db;
@Override
public boolean checkAndIncrementUsage(String ipAddress, String url) throws ExecutionException, InterruptedException {
final DocumentReference docRef = db.collection("daily_usage").document(ipAddress);
final String today = LocalDate.now().format(DateTimeFormatter.ISO_LOCAL_DATE);
ApiFuture<Boolean> future = db.runTransaction(transaction -> {
DocumentSnapshot document = transaction.get(docRef).get();
long currentCount = 0;
if (document.exists() && today.equals(document.getString("lastUpdated"))) {
Long count = document.getLong("count");
if (count != null) {
currentCount = count;
}
}
if (currentCount >= DAILY_LIMIT) {
return false;
}
Map<String, Object> updates = new HashMap<>();
updates.put("lastUpdated", today);
updates.put("count", currentCount + 1);
updates.put("url", url);
transaction.set(docRef, updates, SetOptions.merge());
return true;
});
return future.get();
}
}
위의 클래스에는 firestore 읽기와 쓰기가 들어가 있다.
final DocumentReference docRef = db.collection("daily_usage").document(ipAddress);
데이터베이스 내에 있는 Collection과 Document에 대한 정보를 통해 문서를 가져온다는 의미로 읽으면 된다.
Collection의 이름은 daily_usage이고, 해당 Collection 내의 문서 이름은 ipAddress이다.
ip당 일일 접근 허용량 제한 기능을 만들기 위한 데이터 구조이다.
DocumentSnapshot document = transaction.get(docRef).get();
문서 객체를 트랜잭션을 통해 받아온다. 즉, Read 한다.
transaction.set(docRef, updates, SetOptions.merge());
트랜잭션 내에서 문서에 변경사항을 병합 방식으로 작성한다. 즉, Write 한다.
하여간 위의 로직을 한 번 실행하면...!

위와 같이 데이터가 구조화되어 삽입된 것을 확인할 수 있다.
사실 이거 읽기 쓰기는 조금 초과돼도 큰 부담이 안되긴 하지만...

이와 같이 사용 페이지에 들어가면 일일 사용량이 무료사용량과 함께 제공된다.
MongoDB도 같은 문제가 있는지는 모르지만, 아무래도 비정형 데이터를 다루다 보니 RDBMS 만큼의 정교함은 없는 것 같다.
https://firebase.google.com/docs/firestore/best-practices?hl=ko
Cloud Firestore 권장사항 | Firebase
이제 MongoDB 호환성을 갖춘 Firestore Enterprise 버전을 사용할 수 있습니다. 자세히 알아보기 의견 보내기 Cloud Firestore 권장사항 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하
firebase.google.com
https://firebase.google.com/docs/firestore/solutions/counters?hl=ko
분산 카운터 | Firestore | Firebase
이제 MongoDB 호환성을 갖춘 Firestore Enterprise 버전을 사용할 수 있습니다. 자세히 알아보기 의견 보내기 분산 카운터 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하
firebase.google.com
아무래도 대용량 트래픽이 집중되는 경우, Redis만큼의 성능이 나오지 못하는 건 당연할 것이다.
쓰기 편리하지만, 한계도 명확한 데이터베이스가 아닌가 싶다.
하지만 트래픽이 적은 나 같은 개발자한테는 무료로 쓰기 딱 좋은 정도지...!
'공부' 카테고리의 다른 글
| [html] 웹 개발자를 위한 iframe 사용법과 팁 (feat. 티스토리 연동) (2) | 2025.07.02 |
|---|---|
| [AI] SI 개발자에게 AI의 의미 (4) | 2025.06.26 |
| [BE] Spring AsyncContext - 스프링의 비동기 메시지 인터페이스 (0) | 2025.06.22 |
| [매크로] Java와 이미지 인식을 이용한 게임 매크로 만들어보기 (0) | 2025.06.20 |
| [이미지변환] 도커를 이용한 이미지 변환 (HEIC To JPG) (1) | 2025.06.20 |

